dd post about downtime
Showing
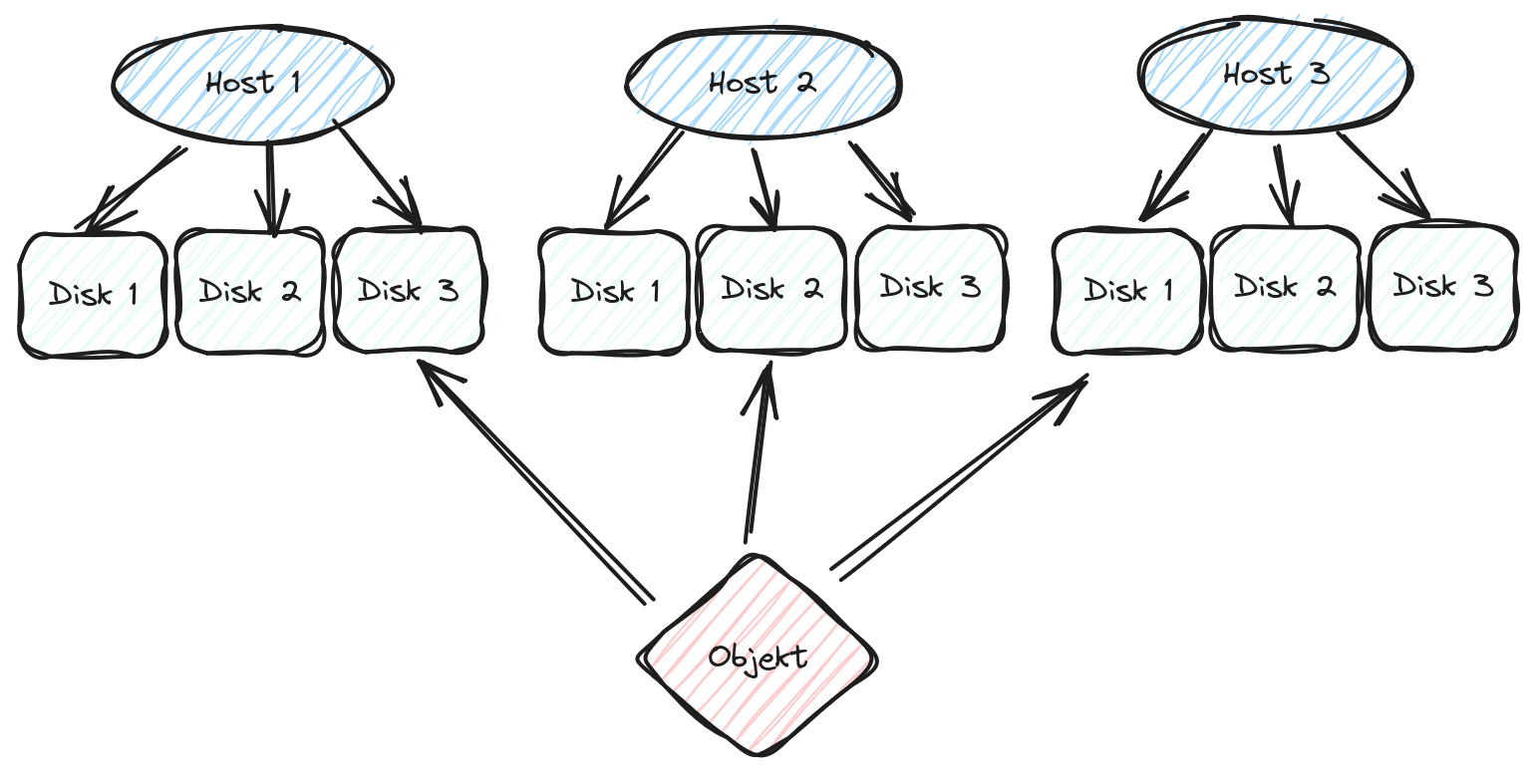
- content/blog/2024/07/2024-07-19_downtime-bericht/ceph-objekte.png 0 additions, 0 deletions...blog/2024/07/2024-07-19_downtime-bericht/ceph-objekte.png
- content/blog/2024/07/2024-07-19_downtime-bericht/index.md 332 additions, 0 deletionscontent/blog/2024/07/2024-07-19_downtime-bericht/index.md
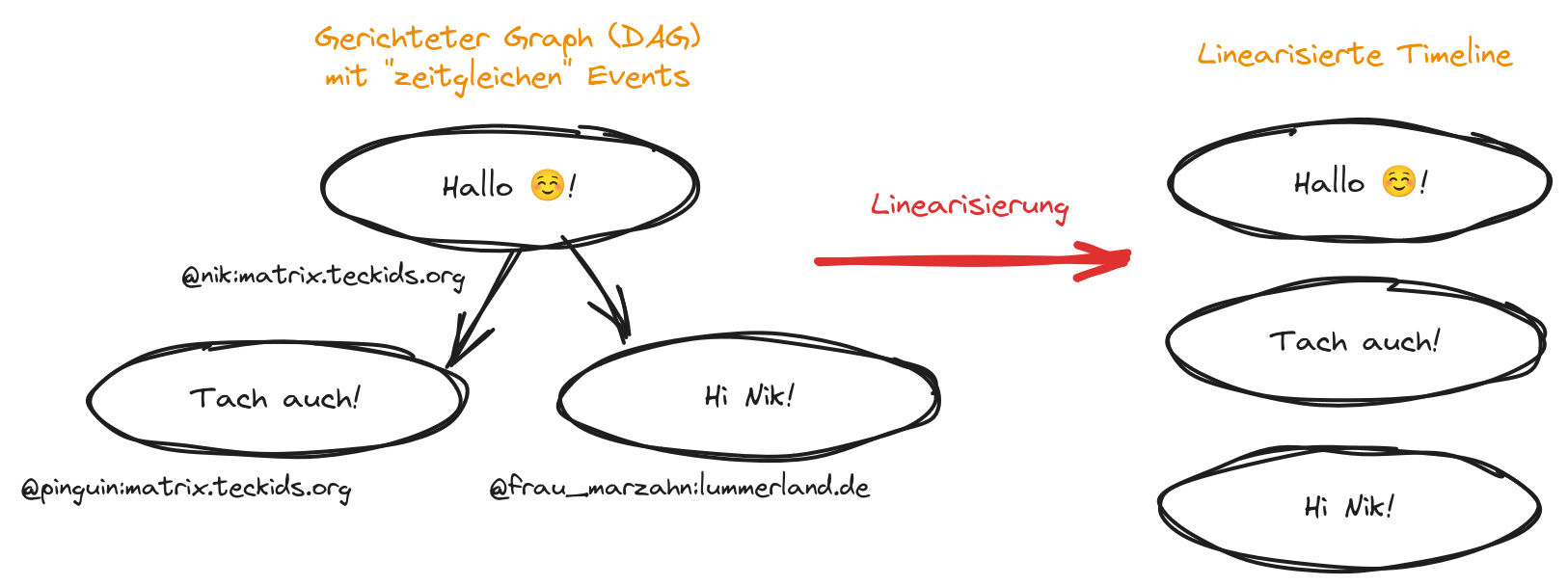
- content/blog/2024/07/2024-07-19_downtime-bericht/matrix-linearisierung.png 0 additions, 0 deletions.../07/2024-07-19_downtime-bericht/matrix-linearisierung.png
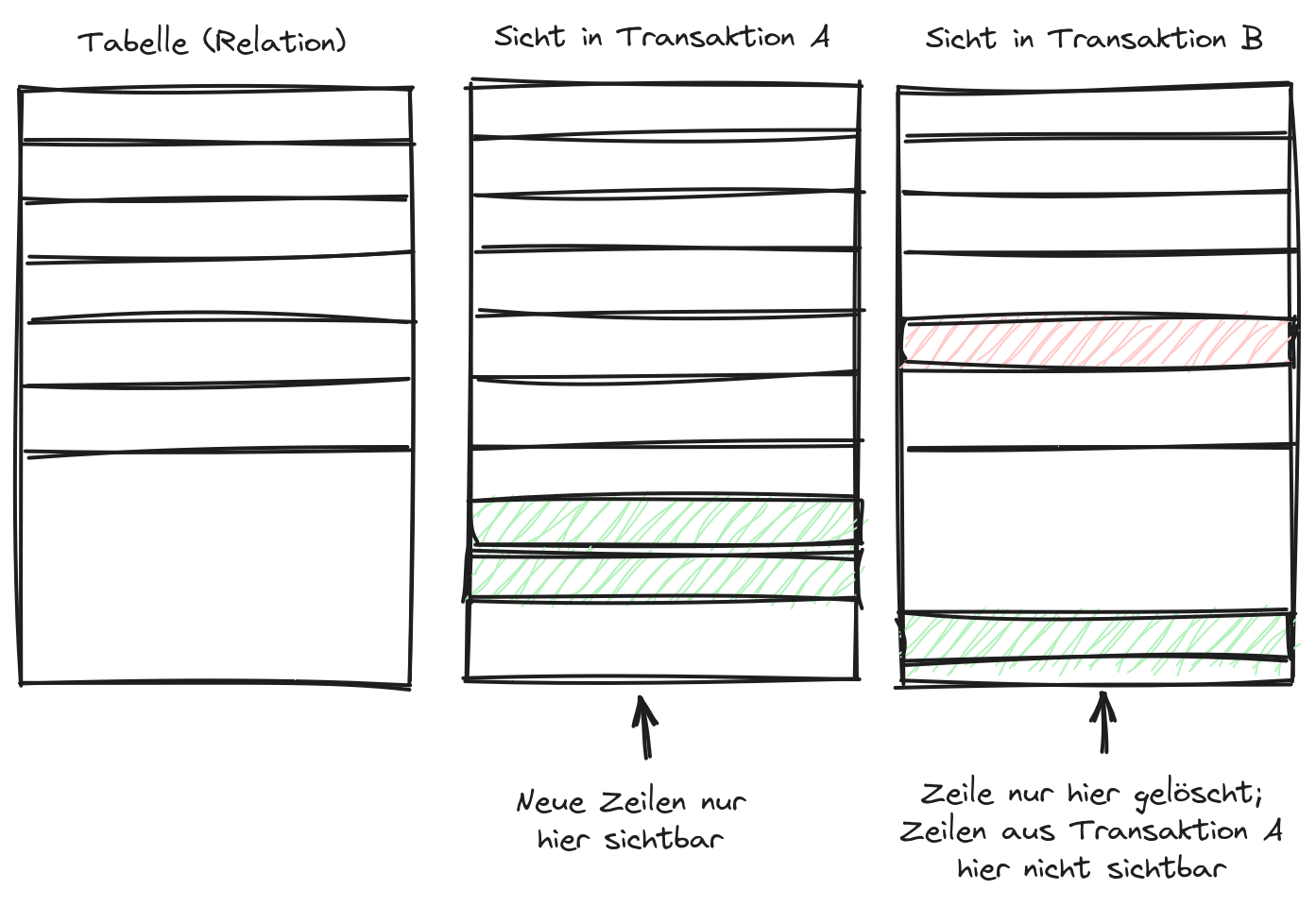
- content/blog/2024/07/2024-07-19_downtime-bericht/pg-transaktionen.png 0 additions, 0 deletions.../2024/07/2024-07-19_downtime-bericht/pg-transaktionen.png
- content/blog/2024/07/2024-07-19_downtime-bericht/rack-sharepic.jpg 0 additions, 0 deletions...log/2024/07/2024-07-19_downtime-bericht/rack-sharepic.jpg
{kind=link}
413 KiB
{kind=link}
165 KiB
{kind=link}
299 KiB
{kind=link}

420 KiB